

On peut vous aider ?
Cherchez des réponses ou parcourez les rubriques de notre documentation
Assemblage des données
{:fr}
Résumé
Lors de l’exécution d’une action de lancement de collecte ou d’une action de lancement de restitution, la création d’un document est réalisée ainsi :
Pour chaque entité définie par la relation d’affectation,
- Le serveur duplique le modèle.
- Un jeu de données comportant, pour l’entité concernée, tous les champs du carnet d’adresses et tous les champs de la relation d’affectation est créé : c’est le noyau.
- Chaque compartiment du document ainsi dupliqué est alimenté par un jeu de données résultant de la jointure entre la source de données du compartiment avec les axes de diffusion.
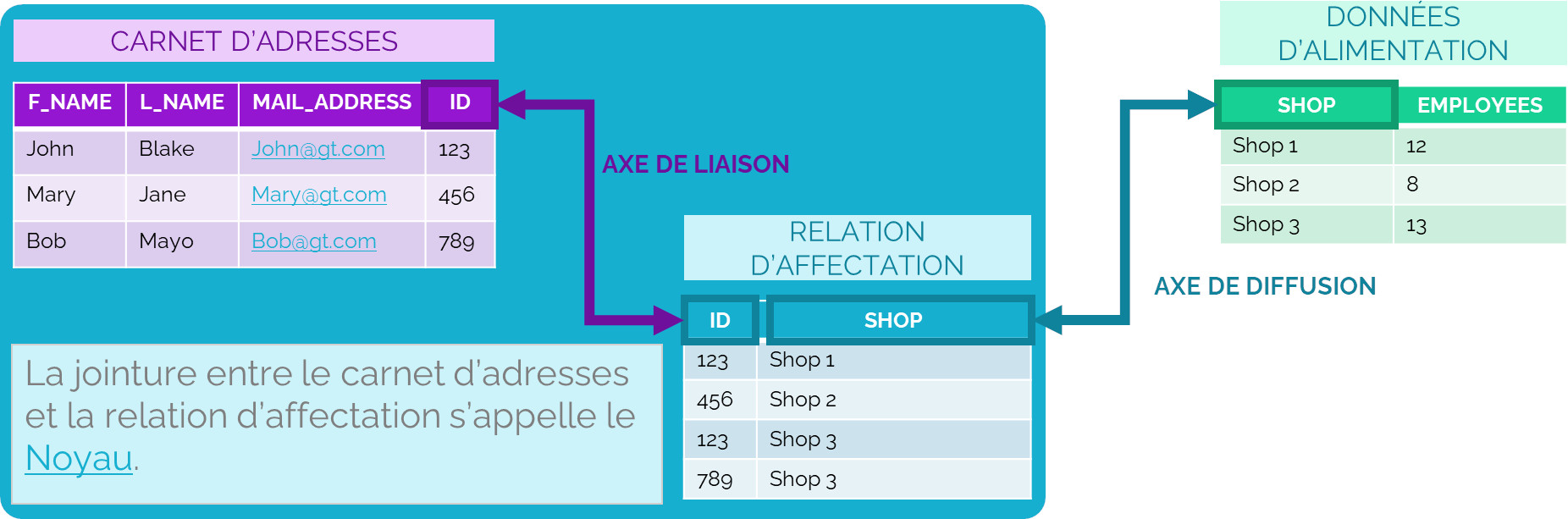
Les axes de diffusion permettent donc de filtrer les données des compartiments. Dans l’exemple fourni par le schéma ci-dessus, le document de l’entité « Shop 1 » recevra la valeur « 12 » pour le champ « EMPLOYEES » grâce à la jointure sur entre l’axe de diffusion « SHOP » et le champ « SHOP » des données d’alimentation. Si l’axe de diffusion n’avait pas été « SHOP » mais « ID », alors cette jointure n’aurait pas été réalisée et le compartiment aurait reçu la totalité des enregistrements contenus dans les données d’alimentation.
Construction du noyau
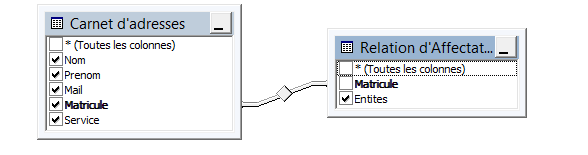
Le noyau est la vue rassemblant les données du carnet d’adresse et de la relation d’affectation.
Les données du noyau sont produites à partir d’une jointure interne entre le carnet d’adresses et la relation d’affectation.
La jointure est effectuée sur l’axe de liaison (cet axe doit être commun au carnet d’adresse et à la relation d’affectation).
Tous les champs de la relation d’affectation sont incorporés dans le noyau.
Les champs du carnet d’adresses qui n’existent pas dans la relation d’affectation sont également incorporés dans le noyau : c’est pourquoi il est nécessaire de veiller à n’y inclure que les champs strictement nécessaires afin de ne pas dégrader inutilement les performances.
Les axes de diffusion et l’axe de liaison avec le carnet d’adresses doivent constituer une clé pour les données du noyau.
Production des blocs de données associés à chaque compartiment
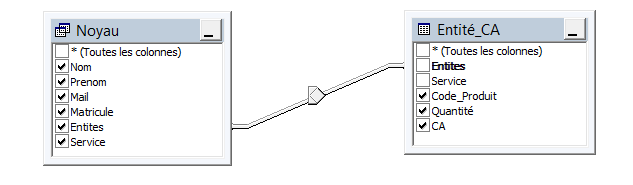
Pour chacune des entités-correspondants (chaque ligne du noyau) :
Pour chacune des tables/vues associées à un compartiment dans l’action de lancement de campagne :
Une jointure externe gauche est réalisée entre le noyau et la table/vue du compartiment.
Cette jointure est effectuée sur les axes communs entre la table/vue du compartiment et les axes de distribution.
Tous les champs de la table qui ne sont pas déjà dans le noyau (donc ni dans le carnet d’adresses ni dans la relation d’affectation) sont ajoutés au bloc de données.
Si un champ existe dans le noyau et dans la table du compartiment, le champ de la table sera ignoré. Si le champ de la table n’a pas la même signification que dans le noyau et que l’on souhaite l’exploiter dans le questionnaire, le champ de la table ou celui du noyau devrait être renommé (et éventuellement les composants en conséquence).
Puisqu’une jointure externe est réalisée entre le noyau et la table du compartiment, la limitation de l’envoi des questionnaires à certaines entités ne peut être effectuée sur la table du compartiment, elle doit être effectuée sur la relation d’affectation.
Le fait de restreindre une table du compartiment à certaines entités ne personnalisera pas les données pour ce compartiment, mais le questionnaire sera quand même envoyé.
Si aucun axe parmi les axes de distribution n’existe dans la table/vue du compartiment, un produit cartésien est réalisé entre le noyau et la table/vue du compartiment.
Dans ce dernier cas, si la table/vue du compartiment ne contient aucune donnée, seules les données du noyau sont produites, les axes de la table du compartiment qui ne sont pas déjà dans le noyau sont ajoutés avec une valeur NULL.
Si la table/vue doit subir un tri (configuré dans l’action de lancement), ce tri est effectué sur le bloc de donnée résultat.
Transposition de chaque bloc de données si nécessaire
Chaque bloc de donnée précédemment construit subit une transposition si le compartiment associé fait référence à une transposition.
Les croisements de dimensions exprimés par la transposition qui n’existent pas dans le questionnaire seront simplement ignorés lors de l’alimentation.
Dans le cas de dates anonymisées, cela peut être un avantage indéniable : le critère de sélection des dates qui peut être difficile à exprimer parfois est en fait exprimé dans le questionnaire (seules les dates anonymisées correspondantes seront produites).
Dans le cas d’axes standards non anonymisés, il vaut mieux avoir une maîtrise complète des modalités de chacune des dimensions (les modalités devront probablement évoluer en relation avec le questionnaire)
Assemblage des blocs produits entre eux dans le questionnaire
L’ensemble constitué des blocs de données précédemment construits pour chaque compartiment et pour une entité-correspondant (une ligne du noyau) est maintenant injecté dans le questionnaire Calame.
Pour chaque compartiment démultipliant des cellules/onglets lors de la personnalisation (multi-onglet et motif), un bloc de donnée (bloc de référence) va déterminer l’ensemble des modalités de référence. Les autres blocs seront assemblés avec les blocs de référence identifiés.
C’est la table/vue associé au compartiment de plus haut niveau qui déterminera les items de référence pour la démultiplication lors de la personnalisation.
Par exemple, si une table est associée à la racine du multi-onglet, c’est elle qui va en déterminer les items de référence.
Ceci signifie que même si la table d’un motif ou d’une transposition dans un multi-onglet contient plus de modalités que les modalités de la table associée à la racine du multi-onglet, les modalités supplémentaires seront ignorées.
Si deux compartiments sont en concurrence (parce qu’au même niveau) pour servir de référence au multi-onglet ou au motif, l’ordre alphabétique des noms des compartiments déterminera la référence.
Une fois les tables de référence choisies pour les données des multi-onglets et des motifs, ceux-ci sont démultipliés suivant les données de ces tables de référence :
Les multi-onglets sont démultipliés suivant l’axe de multi-onglet présent dans la table de référence.
Les motifs sont démultipliés suivant autant de lignes que présentes dans la table de référence.
Les blocs de données venant des autres compartiments sont alors ajoutés pour les items-clés du bloc de référence.
Dans le cas du bloc de référence du multi-onglet et d’un bloc associé à un sous-compartiment du multi-onglet, l’assemblage est effectué en utilisant l’axe de multi-onglet
Dans le cas du bloc de référence d’un motif et d’un bloc associé à une transposition dans ce motif, tous les champs communs aux deux blocs de données sont utilisés pour faire une jointure externe gauche (les items-clés sont les items du bloc de référence se trouvant dans tous les axes communs aux deux blocs)
Si deux transpositions se trouvent dans le motif, il est nécessaire qu’existe un composant dans le motif qui ne soit pas transposé pour servir de référence commune aux deux transpositions.
Ce composant peut être alimenté totalement par l’une des deux transpositions (la première par ordre alphabétique si aucun bloc n’est associé au motif).
Si un axe existe dans la table associée au compartiment parent et dans la table associée au compartiment fils, seule la valeur de la table associée au compartiment parent est prise en compte.
Un bloc associé à un multi-onglet doit contenir l’axe de multi-onglet.
Un champ vide (NULL) dans le bloc de donnée sera interprété comme une absence de personnalisation : la donnée déposée dans le questionnaire pour ce champ/composant sera la donnée définie à la conception.
Il est conseillé de ne pas mettre de valeur par défaut pour les composants à la conception du questionnaire. L’exception étant le contrôle non personnalisable contenant une formule, ce contrôle étant construit avec la fonction gtcontrole.{:}{:en}
Summary
When executing a collection launch action or a restitution launch action, the creation of a document is performed as follows:
For each entity defined by the assignment relationship,
- The server duplicates the template.
- A data set containing all the fields of the address book and all the fields of the assignment relationship is created for the entity concerned: this is the kernel.
- Each compartment of the duplicated document is fed by a dataset resulting from the join between the compartment data source and the diffusion axes.
The diffusion axes, therefore, make it possible to filter the data in the compartments. In the example provided by the diagram above, the document of the « Shop 1 » entity will receive the value « 12 » for the « EMPLOYEES » field thanks to the join between the « SHOP » diffusion axis and the « SHOP » field of the feed data. If the diffusion axis had not been « SHOP » but « ID », then this join would not have been performed and the compartment would have received all the records contained in the feed data.
Building the kernel
The kernel is the view that collects the data from the address book and the assignment relationship.
The kernel data is produced from an internal join between the address book and the assignment relationship.
The join is performed on the linking axis (this axis must be common to both the address book and the assignment relationship).
All fields of the assignment relationship are embedded in the kernel.
The address book fields that do not exist in the assignment relationship are also embedded in the kernel.
The diffusion axes and the axis linking to the address book must be a key to the kernel data.
Production of the data blocks associated with each compartment
For each of the corresponding entities (each row in the kernel) :
For each of the tables/views associated with a compartment in the campaign launch action:
A left outer join is performed between the kernel and the compartment table/view.
This join is performed on the common axes between the compartment table/view and the diffusion axes.
All fields of the table that are not already in the kernel (i.e. neither in the address book nor in the assignment relationship) are added to the data block.
If a field exists in the kernel and in the compartment table, the table field will be ignored. If the table field does not have the same meaning as in the kernel and is to be used in the questionnaire, the table field or the kernel field should be renamed (and possibly the components accordingly).
Since an outer join is performed between the kernel and the bucket table, restricting the sending of questionnaires to certain entities cannot be performed on the compartment table, it must be performed on the assignment relationship.
Restricting a compartment table to certain entities will not customise the data for that compartment, but the questionnaire will still be sent.
If none of the diffusion axes exist in the compartment table/view, a Cartesian product is performed between the kernel and the compartment table/view.
In the latter case, if the compartment table/view does not contain any data, only the kernel data is produced; the axes of the compartment table that are not already in the kernel are added with a NULL value.
If the table/view is to be sorted (configured in the launch action), the sorting is performed on the result data block.
Transposition of each data block if necessary
Each previously constructed data block is transposed if the associated compartment refers to a transposition.
The crossings of dimensions expressed by the transposition that do not exist in the questionnaire will simply be ignored during the feeding.
In the case of anonymised dates, this can be an undeniable advantage: the date selection criterion, which may be difficult to express at times, is, in fact, expressed in the questionnaire (only the corresponding anonymised dates will be produced).
In the case of non-anonymised standard axes, it is better to have complete control over the modalities of each of the dimensions (the modalities will probably have to evolve with respect to the questionnaire).
Assembling the blocks produced between them in the questionnaire
The set of data blocks previously constructed for each compartment and a corresponding entity (a row in the kernel) is now injected into the Calame questionnaire.
For each compartment that multiplies cells/sheets during customisation (multi-tab and pattern), a data block (reference block) will determine the set of reference modalities. The other blocks will be assembled with the identified reference blocks.
It is the table/view associated with the highest level compartment that will determine the reference items for the multiplication during customisation.
For example, if a table is associated with the root of the multi-tab, it will determine the reference items.
This means that even if the table of a pattern or transposition in a multi-tab contains more items than the items in the table associated with the root of the multi-tab, the additional items will be ignored.
If two compartments are competing (because they are at the same level) to serve as references for the multi-tab or pattern, the alphabetical order of the compartment names will determine the reference.
Once the reference tables have been chosen for the data of the multi-tabs and patterns, the latter are demultiplied according to the data of these reference tables:
Multi-tabs are scaled-down along the multi-tab axis present in the reference table.
The patterns are scaled-down along as many rows as are present in the reference table.
The data blocks from the other compartments are then added for the key items of the reference block.
In the case of the multi-tab reference block and a block associated with a sub-compartment of the multi-tab, the assembly is performed using the multi-tab axis
In the case of the reference block of a pattern and a block associated with a transposition in this pattern, all fields common to both data blocks are used to make a left outer join (the key items are the items of the reference block that are found in all axes common to both blocks)
If there are two transpositions in the pattern, it is necessary that there is a component in the pattern that is not transposed to serve as a common reference for both transpositions.
This component can be fed completely by one of the two transpositions (the first one in alphabetical order if no block is associated with the pattern).
If an axis exists in the table associated with the parent compartment and in the table associated with the sub-compartment, only the value of the table associated with the parent compartment is taken into account.
A block associated with a multi-tab must contain the multi-tab axis.
An empty field (NULL) in the data block will be interpreted as an absence of customisation: the data deposited in the questionnaire for this field/component will be the data defined during design.
It is advisable not to set a default value for components during questionnaire design. The exception is the non-customisable control containing a formula, this control being built with the gtcontrol function.{:}